



Originally published on Brookings
If you have ever used a smartwatch or other wearable tech to track your steps, heart rate, or sleep, you are part of the “quantified self” movement. You are voluntarily submitting millions of intimate data points for collection and analysis. The Economist highlighted the benefits of good quality personal health and wellness data—increased physical activity, more efficient healthcare, and constant monitoring of chronic conditions. However, not everyone is enthusiastic about this trend. Many fear corporations will use the data to discriminate against the poor and vulnerable. For example, insurance firms could exclude patients based on preconditions obtained from personal data sharing.
Can we strike a balance between protecting the privacy of individuals and gathering valuable information? This blog explores applying a synthetic populations approach in New York City, a city with an established reputation for using big data approaches to support urban management, including for welfare provisions and targeted policy interventions.
To better understand poverty rates at the census tract level, World Data Lab, with the support of the Sloan Foundation, generated a synthetic population based on the borough of Brooklyn. Synthetic populations rely on a combination of microdata and summary statistics:
- Microdata consists of personal information at the individual level. In the U.S., such data is available at the Public Use Microdata Area (PUMA) level. PUMA are geographic areas partitioning the state, containing no fewer than 100,000 people each. However, due to privacy concerns, microdata is unavailable at the more granular census tract level. Microdata consists of both household and individual-level information, including last year’s household income, the household size, the number of rooms, and the age, sex, and educational attainment of each individual living in the household.
- Summary statistics are based on populations rather than individuals and are available at the census tract level, given that there are fewer privacy concerns. Census tracts are small statistical subdivisions of a county, averaging about 4,000 inhabitants. In New York City, a census tract roughly equals a building block. Similar to microdata, summary statistics are available for individuals and households. On the census tract level, we know the total population, the corresponding demographic breakdown, the number of households within different income brackets, the number of households by number of rooms, and other similar variables.
The difficulty with this arrangement is that as microdata is only available at the larger PUMA level, differences between the census tracts within that PUMA are not visible. For example, policymakers could miss out on income disparities within the same neighborhood. Using a synthetic populations approach, we can combine these two datasets to simulate the actual distribution without infringing on people’s privacy.
Synthetic populations are a combination of actual microdata and summary statistics. We use variables that we have both as actual microdata and as summary statistics (e.g., number of households, the demographic breakdown of the population, or the household income by brackets) to sample from the microdata in such a way that the constraints from the summary statistics (e.g., total number of people and households within a census tract) are fulfilled. By controlling for as many variables as possible, we create a representative micro dataset on the census tract level. This dataset then allows us to explore heterogeneity across different census tracts within a PUMA and to answer more detailed questions (e.g., how does income differ by age and sex within a census tract). While we can only control for variables included in both datasets, the resulting synthetic population also has information on all other variables included in the original microdata on the PUMA level.
Figure 1. Brooklyn by building block—with synthetic populations
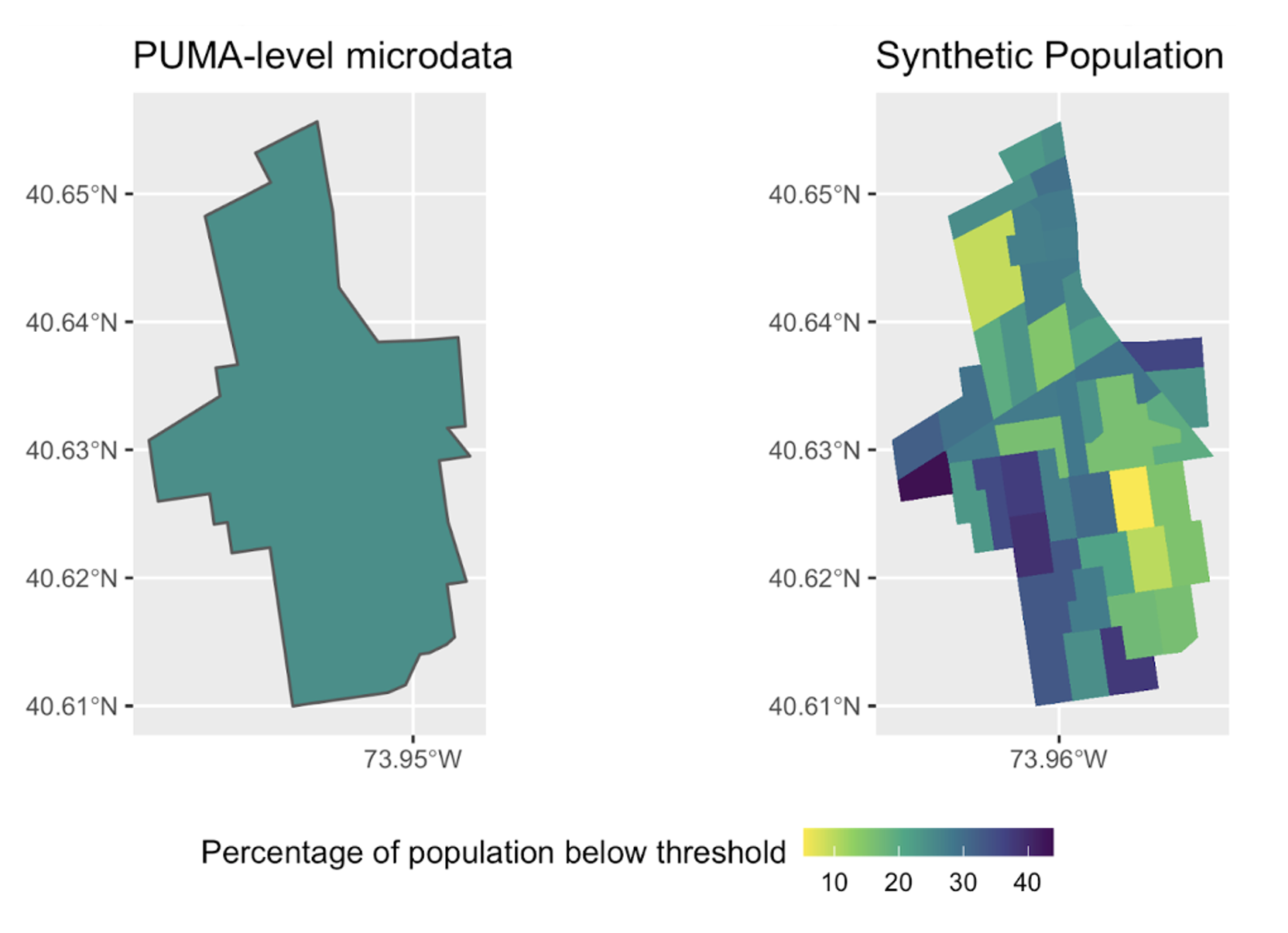
Note: Population living below NYC-specific (Flatbush and Midwood in Kings County PUMA, Brooklyn) poverty threshold, PUMA-level microdata vs. synthetic population. On the PUMA-level map, the average poverty rate is 26.4 percent. In the Synthetic Population map, the poverty rate varies from below 10 percent to above 40 percent.
In this example, the PUMA Flatbush and Midwood in Kings County, NYC, was chosen due to its high variance across mean income. It consists of 44 census tracts, containing around 57,000 total households and 155,000 people.
Figure 1 shows that, on average, using the PUMA level microdata, around 26.4 percent of its population live below New York’s poverty threshold. However, using the synthetic populations approach, we can see that some census tracts (23 percent) have significantly lower poverty levels than the average, and some (21 percent) have higher poverty levels than average.
New York City has already made strides in using big data to target its social programs. For example, the Center for Innovation Through Data Intelligence (CIDI) launched The NYC Wellbeing Index at the Neighborhood Tabulation Area (NTA) level to provide an understanding of how neighborhoods compare, help leaders focus strategies in a specific geographic area, and allow for a more manageable assessment of outcomes. NTAs, however, at approximately 15,000 residents, are less granular than census tracts. Understanding which census tracts have the highest proportion of households living beneath the poverty line could allow for more targeted and cost-effective delivery of social programs.
This method also holds promise for developing counties and emerging markets as (geographic) granularity is often lacking in traditional poverty analysis which would help in more precise targeting as average poverty rates have often been falling, especially in urban areas. Countries such as Philippines, Thailand and Colombia have already been experimenting with such hyper-granular granular poverty-mapping methods which could be brought to the next level with the adoption of synthetic populations.
Overall, synthetic populations can give us the granularity we need to support targeted interventions, maintain privacy, and open up new opportunities beyond traditional poverty research, such as analyzing consumption patterns. We must continue exploring and developing these approaches to improve our understanding of complex urban challenges.
